сЂІсЂфсѓіТўћ сЂесЂѓсѓІтђІС║║С╝џуцЙсЂІсѓЅсЂ«СЙЮжа╝сЂДСйюТѕљсЂЌсЂЪ VBAсЃЌсЃГсѓ░сЃЕсЃасЂїсЂѓсЂБсЂЪсђѓ
сЂЮсЂЊсЂІсѓЅС╗ісЂДсѓѓ 1т╣┤сЂФСйЋт║дсЂІсђЂсЂесЂёсЂєуеІт║дсЂ«уЏИУФЄсѓётЋЈсЂётљѕсѓЈсЂЏсЂїТЮЦсѓІсѓЊсЂасЂїсђЂС╗ітЏъсЂ»тЄдуљєсЂЌсЂЪухљТъюТќЄтГЌсЂїтїќсЂЉсѓІсЂесЂёсЂєтЋЈжАїсЂасЂБсЂЪсђѓсѓѓсЂєТюђухѓсЂ«С┐«ТГБсЂІсѓЅ1т╣┤С╗ЦСИіухїжЂјсЂЌсЂдсђЂсЂЊсѓїсЂЙсЂДсЂ»тЋЈжАїсЂфсЂІсЂБсЂЪсЂ«сЂФсђђсЂёсЂЇсЂфсѓіуЎ║ућЪсЂЌсЂЪсЂ«сЂДтцДТќ╣УфГсЂ┐УЙ╝сѓђсЃЄсЃ╝сѓ┐сЃЋсѓАсѓцсЃФ(CSV)сЂ«тЋЈжАїсЂасѓЇсЂєсЂежФўсѓњсЂЈсЂЈсЂБсЂдсђЂтЋЈжАїсЃЋсѓАсѓцсЃФсѓњжђЂС╗ўсЂЌсЂдсѓѓсѓЅсЂБсЂЪсђѓ
тЄдуљєсЂесЂЌсЂдсЂ»жАДт«бсЂІсѓЅжђЂсѓЅсѓїсЂдсЂЈсѓІ CSVсЃЋсѓАсѓцсЃФсѓњТќ░УдЈсѓисЃ╝сЃѕсЂФУфГсЂ┐УЙ╝сѓЊсЂДсђЂсѓйсЃ╝сЃѕсЃ╗тї║тѕєсЂЉсЂфсЂЕсѓњсЂЎсѓІсЃъсѓ»сЃГсѓ│сЃ╝сЃЅсЂфсѓЊсЂасЂїсђЂжЏ╗УЕ▒сѓњтЈЌсЂЉсЂЪТЎѓсЂ»сЂдсЂБсЂЇсѓіТќЄтГЌсѓ│сЃ╝сЃЅсЂїуЋ░сЂфсЂБсЂдсЂёсѓІ CSVсЃЋсѓАсѓцсЃФсЂїжђЂсѓЅсѓїсЂдсЂЇсЂЪсЂ«сЂДсЂ»№╝ЪсЂеТђЮсЂБсЂЪсђѓсЂесЂЊсѓЇсЂїтЋЈжАїсЂ«сЃЋсѓАсѓцсЃФсѓњУдІсЂдсЂ┐сѓІсЂеТГБтИИтЄдуљєсЂЋсѓїсѓІсЃЋсѓАсѓцсЃФсЂеТќЄтГЌсѓ│сЃ╝сЃЅсѓѓТћ╣УАїсѓ│сЃ╝сЃЅсѓѓтї║тѕЄсѓіТќЄтГЌсѓѓ""(сЃђсЃќсЃФсѓ»сѓЕсЃ╝сЃєсЃ╝сѓисЃДсЃ│тЏ▓сЂё)сѓѓтЁесЂЈтљїСИђсЂфсЂ«сЂФсђЂсЂфсЂюсЂІсЃЄсЃ╝сѓ┐сЂ«жђћСИГсЂІсѓЅТ╝бтГЌсѓ│сЃ╝сЃЅсЂїтцЅтїќсЂЌсЂдсЂЌсЂЙсЂєсђѓ
тйЊтѕЮсЂЊсЂ«сЃъсѓ»сЃГсЂ«тѕХСйюСЙЮжа╝сѓњтЈЌсЂЉсЂЪсЂесЂЇсЂ»жАДт«бсЂ«сѓисѓ╣сЃєсЃасЂї Unixу│╗сЂесЂёсЂєсЂЊсЂесЂДТќЄтГЌсѓ│сЃ╝сЃЅсЂ» Shift_JISсЂасЂЉсЂДсЂ»сЂфсЂЈ Unicode сѓѓТЃ│т«џсЂЌсЂдТќЄтГЌсѓ│сЃ╝сЃЅсЂїУЄфтІЋтѕцтѕЦтЄ║ТЮЦсѓІсѓѕсЂєсЂФсЂесђЂтЁЃсЂФсЂфсѓІсѓ│сЃ╝сЃЅсЂ»СйЋтЄдсЂІсЂ«WebсЂІсѓЅТІЙсЂБсЂдсЂЇсЂдтѕЕућесЂЌсЂЪсѓѓсЂ«сЂасЂБсЂЪсЂ«сЂДсђЂУДБУфГсЂФУІдті┤сЂЌсЂцсЂцуЈЙУ▒АсѓњУ┐йсЂёсЂІсЂЉсЂЪсђѓ
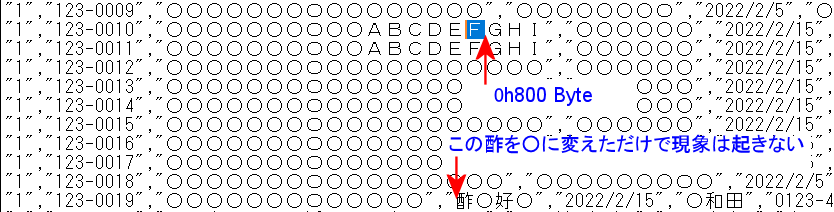
сЂЮсЂ«уЈЙУ▒АсЂ»сђЂтЁЃсЂ«сЃЋсѓАсѓцсЃФсЂї Shift_JISсЂДсЃљсѓцсЃісЃфсЂДжќІсЂёсЂЪта┤тљѕсЂ« 0h800 ByteуЏ«сЂї 2Byteсѓ│сЃ╝сЃЅсЂДсђЂсЂЮсѓїС╗ЦтцќсЂ«тЏъсѓісЂ«2Byteсѓ│сЃ╝сЃЅсЂесЂ«ухёсЂ┐тљѕсѓЈсЂЏсЂДуЈЙУ▒АсЂїУхисЂЇсЂдсЂёсѓІсѓѕсЂєсЂфТёЪсЂўсЂасђѓтЄдуљєСИГсЂДТќЄтГЌсѓ│сЃ╝сЃЅсѓњ Shift_JIS"сЂетЏ║т«џсЂЌсЂдсЂЌсЂЙсЂѕсЂ░уЈЙУ▒АсЂ»УхисЂЇсЂфсЂёсЂїсђЂ"Auto" сЂДТќЄтГЌсѓ│сЃ╝сЃЅтѕцт«џсЂЌсѓѕсЂєсЂесЂЌсЂд Shift_JIS сЂ«тѕцт«џсЂїтЄ║ТЮЦсЂџ РђЮAuto" сЂ«сЂЙсЂЙсЂасЂеУхисЂЇсѓІсђѓсЂЌсЂІсЂЌсЃЄсЃ╝сѓ┐сЂ«жаГсЂ«жЃетѕєсЂ»сЂАсѓЃсѓЊсЂе Shift_JISсЂДУфГсЂ┐УЙ╝сѓЂсЂдсЂёсѓІсЂ«сЂФсђЂуЈЙУ▒АсЂїУхисЂЇсѓІта┤тљѕсЂ» 0h800 ByteуЏ«сЂї уЅ╣т«џсЂ« 2Byteсѓ│сЃ╝сЃЅсЂасЂе сЂЮсЂ«СИіСйЇByteсЂ« "8x"сѓё"9x"(xсЂ»0-FсЂ«сЃўсѓГсѓхтђц)сЂї сЂЎсЂ╣сЂд"3F"сЂФсЂфсЂБсЂдсЂЌсЂЙсЂёсђЂсЂЮсѓїС╗ЦжЎЇсЂ«2Byteсѓ│сЃ╝сЃЅсЂ«СИіСйЇByteсѓѓтЁесЂд"3F" сЂФтцЅтїќсЂЌсЂдсЂЌсЂЙсЂєсђѓ
0h800 уЋфтю░сЂ«ТќЄтГЌсѓ│сЃ╝сЃЅсЂасЂЉсЂїтЋЈжАїсЂасЂесЂІсЂДсЂ»сЂфсЂЈсђЂжЏбсѓїсЂЪта┤ТЅђсЂ«ТќЄтГЌсѓњтцЅтїќсЂЋсЂЏсЂдсѓѓуЈЙУ▒АсЂїУхисЂЇсЂЪсѓіУхисЂЇсЂфсЂІсЂБсЂЪсѓісЂДсђЂТј┤сЂ┐сЂЕсЂЊсѓЇсЂїсЂфсЂёсђѓтйЊуёХС╗ісЂЙсЂДсЂџсЂБсЂетЋЈжАїсЂ»УхисЂЇсЂфсЂІсЂБсЂЪсЂесЂёсЂєсЂЊсЂесЂДсђЂShift_JISсЂДсѓѓсЂ╗сЂесѓЊсЂЕсЂ«сЃЋсѓАсѓцсЃФсЂДсЂ»уЈЙУ▒АсЂїУхисЂЇсЂфсЂёсђѓ
ухљт▒ђсђђуюЪсЂ«тјЪтЏаУ┐йТ▒ѓсЂ»УФдсѓЂсЂдсђЂт»ЙуГќсЂесЂЌсЂдсЂ»сђЂтЄдуљєсЂЎсѓІCSVсЃЋсѓАсѓцсЃФсЂ«тЁѕжаГС╗ўУ┐ЉсЂ«жаЁуЏ«тљЇсЂ«сѓѕсЂєсЂфТќЄтГЌсЂїтЏ║т«џсЂЋсѓїсЂдсЂёсѓІТ╝бтГЌсѓ│сЃ╝сЃЅсЂДТќЄтГЌсѓ│сЃ╝сЃЅсѓњтѕцтѕЦсЂЌсЂд"Shift_JIS"сЂ«тѕцт«џсѓњжќЊжЂЋсЂѕсЂфсЂёсѓѕсЂєсЂФсЂЎсѓІсЂЊсЂесЂДСИђС╗ХУљйуЮђсЂЌсЂЪсЂїсђЂсЂЮсЂ«тЙї WebсЂДУф┐сЂ╣сЂфсЂїсѓЅсЃєсѓ╣сЃѕсЂЌсЂЪсЂесЂЊсѓЇсђЂ
сЂЊсЂЊсЂ«сѓхсЃ│сЃЌсЃФсЂфсѓЅтЋЈжАїсЂфсЂЋсЂЮсЂєсЂасЂетѕєсЂІсЂБсЂЪсђѓ
УдЂсЂ»ТќЄтГЌсѓ│сЃ╝сЃЅсѓњтѕцт«џсЂЌсЂЪсѓЅ ADODB.Stream сЂДУфГсЂ┐УЙ╝сѓђсЂ«сЂ» UTF-8/8nсЂасЂЉсЂДсђЂShift_JISсЂфсЂЕсЂ» FileSystemObject сЂ« OpenTextFile()сЃАсѓйсЃЃсЃЅсѓњСй┐сЂБсЂдУфГсЂ┐УЙ╝сѓђсЂесЂёсЂєсѓѓсЂ«сђѓС╗ќсЂ« WebТЃЁта▒сЂДсЂ»тЁесЂдсЂ«ТќЄтГЌсѓ│сЃ╝сЃЅсѓњ ADODB.Stream сЂДтЄдуљєсЂЎсѓІТќ╣Т│ЋсЂїсѓхсЃ│сЃЌсЃФсЂесЂЌсЂдТј▓У╝ЅсЂЋсѓїсЂдсЂёсѓІсЂїсђЂсЂЕсЂєсѓёсѓЅсЂЮсѓїсЂДсЂ»сЃђсЃАсѓЅсЂЌсЂёсђѓ